
Nurses bargain the override 🛑, CMS scolds its own AI 📋, CDS gains vanish 🌫️


Is “human in the loop” a safety feature, or just a place to put the blame?
Dr. Sam Ashoo — an EM physician and clinical informaticist — draws a line this week between two ways to protect a clinician’s judgment: a nicely-worded principle, and a clause in a contract.
The National Nurses United “Nurses and Patients’ Bill of Rights” asserts a right to override AI decisions “without the threat of discipline or discharge.” Every professional society has a version of that sentence.
The problem: a mission statement has never once stopped a manager. A contract can.
Here’s the part builders skip. Operational AI — acuity scoring, predictive staffing, automated adjudication — is often sold to a CFO because it can’t be easily overridden. Non-negotiability isn’t a bug in that sale. It’s the pitch. One health system cut contract-labor spend 15% within six months of turning on predictive staffing; the savings depend on the algorithm winning the argument.
So when we draw “human in the loop” on the architecture slide, we should be honest about which human, with what authority, absorbing what risk when they hit override. If the answer is “a nurse who gets written up for deviating,” the loop is decorative.
😤 “Unions are self-interested — this is a labor play dressed up as patient safety.” Sure, it’s a labor play. It’s also the only enforceable override protection currently at the bedside, which tells you something uncomfortable about how weak the voluntary ones are. Two things can be true.
😤 “Our tool always lets the clinician override.” Letting them click “dismiss” isn’t the same as protecting them when they do it 40 times a shift and someone runs the report. Design the override; then go find out what happens to the person who uses it.
Interactives
https://www.clinicians.dev/interactives/

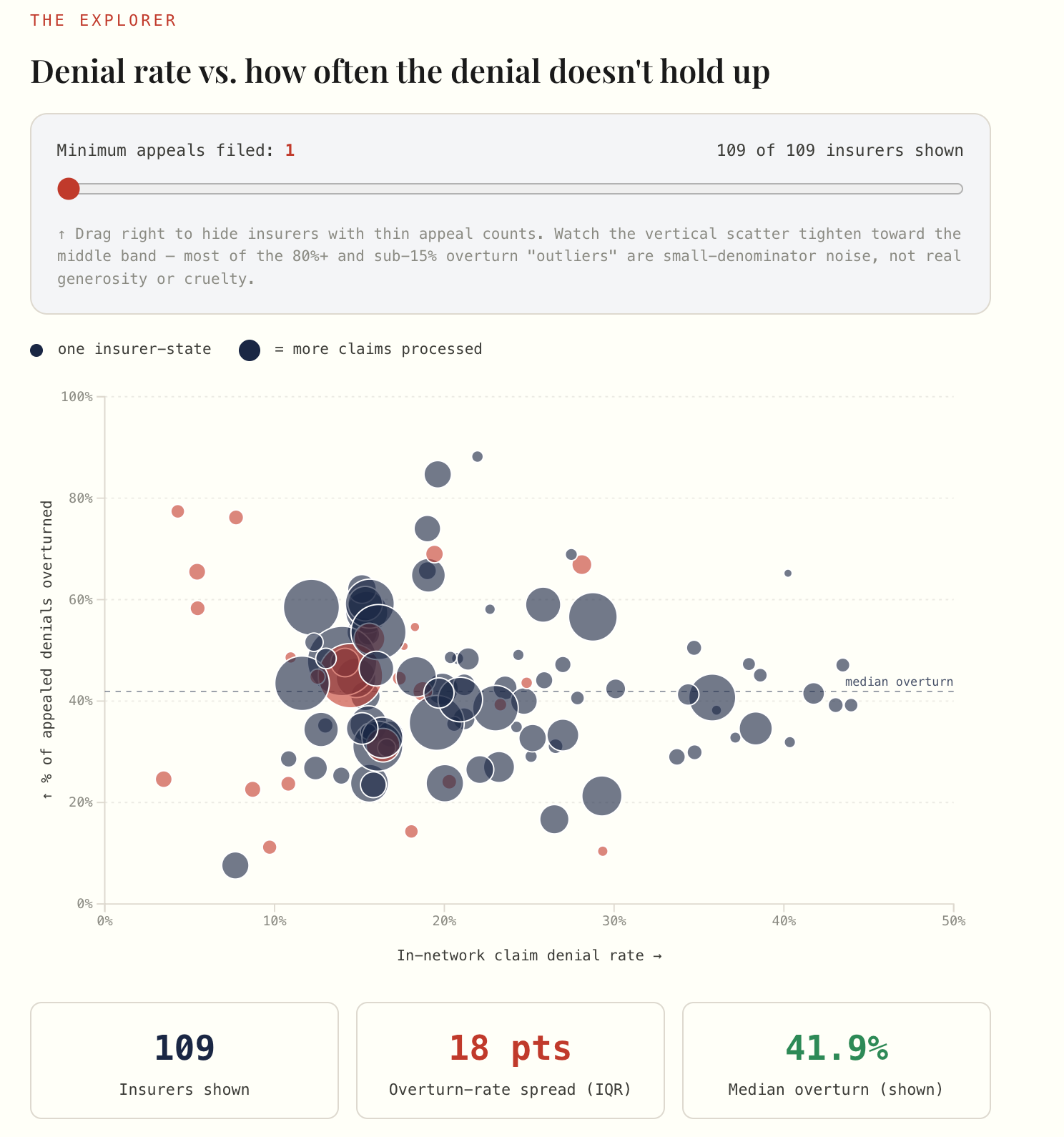
CMS just reprimanded its own AI — in Medicare.
Six months into the WISeR prior-authorization pilot, CMS ordered its contractor Virtix Health to file a Corrective Action Plan for missing turnaround-time standards. Reporting indicates all six pilot states and all six contractors fell short, and 60+ members of Congress are moving to wind the program down.
This is the government running the exact automated-denial playbook it lets Medicare Advantage plans run — and stumbling on the boring part, turnaround time, not the AI part.
The failure mode wasn’t a hallucination. It was an SLA.
😤 “So AI prior auth doesn’t work?” It means this one missed its clock. Read that as a spec, not an obituary.
The effect vanished before it reached the patient.
The most rigorous test yet of embedded LLM decision support — a cluster-randomized trial of GPT-4o “AI Consult” across 16 Penda Health clinics, published in Nature Medicine — found no significant difference in 14-day treatment failure (2.2% vs 2.0%). The trial defined treatment failure as any of the following events within 14 days of an encounter: persistent symptoms requiring a return visit, an unplanned escalation to emergency care, or a clinically significant safety event (e.g., a missed diagnosis, inappropriate prescription, or severe adverse outcome).
Clinicians fully followed only 19.5% of the appropriate red alerts. (Red alerts were prompted when the LLM’s analysis indicated that the documentation, diagnosis, or treatment plan was incorrect or potentially harmful)
This trial ran in Kenya, not the US, so hold the generalization loosely — but the shape of the result is the lesson: an alert nobody acts on is an override by omission.
💡 80/20: Stop reporting “accuracy.” Report action rate — what fraction of the model’s correct, high-priority flags actually changed a decision. Build that number into your eval from day one; it’s the only one that separates a tool that helps from a tool that documents.

This week’s cost lesson: route, don’t just pick.
Two signals landed together. Meta imposed internal caps on token spend after 2026 inference costs approached the billions — and if a hyperscaler is rationing tokens, your side project has no excuse. In the same window, Nate Jones published a “model-picker” routing prompt that sends each task to the cheapest model that can still do it well.
💡 80/20: For any clinical workflow, most steps don’t need your best model — triage-routing a summarization step to a small model and reserving the frontier model for the reasoning step can cut cost by an order of magnitude with no quality loss you’d notice. Meter it per-task, not per-app.
The security agents are here — and so are the models that make them necessary.
Cognition launched Devin Security Swarm, an agent that scans a codebase, tests whether a vulnerability is actually exploitable, and opens the fix PR itself. Meanwhile a researcher argues the GLM-5.2 open-weight model is a genuine security emergency precisely because its safeguards strip off so easily.
😤 “Autonomous agents fixing my security? Hard pass.” Fair — an agent that can write the fix can write the hole. But if you’re a clinician shipping healthcare code, “I ran an exploitability scan on every PR” is a sentence your security review wants to hear. Supervised, on non-PHI repos, this is a gate, not a co-pilot.
Ultra-shorts:
Together AI raised an $800M Series C at an $8.3B valuation, adding ~500 MW of compute — the open-model inference layer keeps consolidating capital.
xAI shipped a no-code Grok Voice Agent Builder at roughly $0.05/min. Patient-reminder and intake lines just got a weekend-project price tag (synthetic data only — do not point this at a real panel without a BAA).
🎙️ From the Pods
🎙️ The 229 Podcast — “Why the Browser Is Your Health System’s Biggest Security Gap” (This Week Health, w/ Andrew Rollo)
The browser — not the endpoint — is now where the clinical data actually lives, which means your browser update cadence is your real vulnerability-patch cycle. Schedule a 10,000-endpoint browser refresh around network load, not against it, or you’ll starve the EHR at the wrong hour.
🔇 Speaker Blindspot: Appeal to authority plus a quiet false dichotomy — a Chrome Enterprise engineer frames the managed enterprise browser as the inevitable answer to a threat he’s also defining, skipping past thin-client, VDI, and app-isolation alternatives entirely.
🎙️ Tradeoffs — “Making Medical Decisions with Uncertain Science” (Aspen Ideas Health panel)
As AI gets embedded everywhere, informed consent is quietly collapsing into mere disclosure, and the field hasn’t decided whether that’s acceptable. The panel’s sharpest line for builders: “the algorithm is trained to sound certain,” which hands clinicians an uphill battle against a confident machine.
🔇 Speaker Blindspot: False equivalence — “rejecting AI is like refusing electricity in the ER” smuggles inevitability past the very consent debate the panel is trying to have. Electricity has no bias, no accountability gap, and no de-skilling risk; AI has all three.
What are you building this week? Email and tell me (kevin@clinicians.build) — I read every one.
— Kevin & AI